Идем в машинное отделение.
 Изучая языки программирования (в школе – Pascal, в университете, в рамках образовательной программы – C++, на данный момент - Python), я всегда задавался вопросом: “а как оно все происходит там, уровнем ниже, в машинном отделении, так сказать?” Ведь одно дело учить синтаксис и команды высокоуровневого языка программирования интуитивно понятные человеку, а другое – хотя бы в общих чертах представлять, как все устроено там, “под капотом”.
Если мы спустимся на “этаж” ниже от привычного нам уровня приложений, с понятным нам интерфейсом, то первым, в чем предстоит нам разобраться – это взаимодействие памяти и процессора. Конечно, погружаться очень глубоко в данный вопрос, в рамках данной статьи, я не стану, но в общих чертах попробую описать, как понимаю это я.
Допустим, мы написали код некоторой программы. Наш код скомпилировался в исполняемый файл (.EXE для семейства ОС Windows). Структуру готового исполняемого файла я привел ниже:
Изучая языки программирования (в школе – Pascal, в университете, в рамках образовательной программы – C++, на данный момент - Python), я всегда задавался вопросом: “а как оно все происходит там, уровнем ниже, в машинном отделении, так сказать?” Ведь одно дело учить синтаксис и команды высокоуровневого языка программирования интуитивно понятные человеку, а другое – хотя бы в общих чертах представлять, как все устроено там, “под капотом”.
Если мы спустимся на “этаж” ниже от привычного нам уровня приложений, с понятным нам интерфейсом, то первым, в чем предстоит нам разобраться – это взаимодействие памяти и процессора. Конечно, погружаться очень глубоко в данный вопрос, в рамках данной статьи, я не стану, но в общих чертах попробую описать, как понимаю это я.
Допустим, мы написали код некоторой программы. Наш код скомпилировался в исполняемый файл (.EXE для семейства ОС Windows). Структуру готового исполняемого файла я привел ниже:
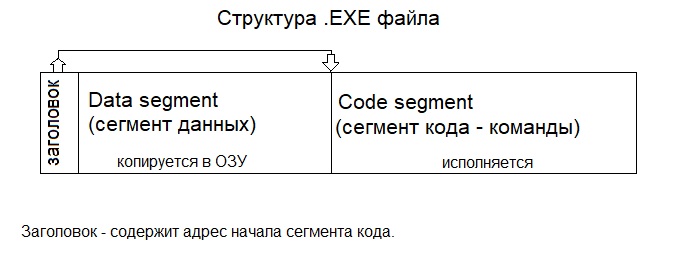
Как мы видим, EXE файл представляет собой несколько сегментов с разным назначением. Данная структура делит нашу программу на сегмент данных и сегмент кода.
Память (ОЗУ) – это последовательность байт. Доступ к памяти (ячейкам) может осуществляться как к одному непрерывному массиву (модель flat), или как к нескольким массивам (сегментированная модель).
Итак, что же происходит при запуске программы? Операционная система (ОС) выделяет необходимый объем памяти. Другими словами – создается процесс, то есть выделяются и разграничиваются ресурсы. Затем ОС загружает в выделенную область памяти нашу программу, которая представляет из себя, как мы уже знаем, сегменты данных и команд (инструкций). Далее происходит передача управления нашей программе, то есть выполнение инструкций. Другими словами, создается поток.
Поток использует ресурсы процесса и определяет последовательность исполнения кода в соответствующем сегменте.
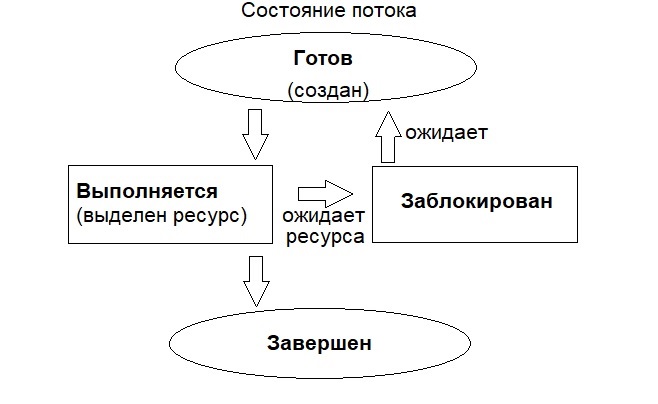 Внутри одного процесса может быть несколько потоков и выполняться они могут параллельно. Например, всем известная функция main() запускает главный поток. Остальные потоки запускаются (создаются) при помощи других функций по мере необходимости и усмотрению программиста при написании кода.
При загрузке процесса в ОЗУ формируется адресное пространство этого процесса, которое состоит из различных сегментов. Ниже на схеме, я попытался доступно это отразить:
Внутри одного процесса может быть несколько потоков и выполняться они могут параллельно. Например, всем известная функция main() запускает главный поток. Остальные потоки запускаются (создаются) при помощи других функций по мере необходимости и усмотрению программиста при написании кода.
При загрузке процесса в ОЗУ формируется адресное пространство этого процесса, которое состоит из различных сегментов. Ниже на схеме, я попытался доступно это отразить:

Теперь мы немного представляем, как устроена организация ресурсов памяти выделенной под конкретный процесс. Но как происходят непосредственно операции - вычисления над данными, которые там хранятся? Иначе говоря, мы рассмотрели структуру склада данных, но еще не видели организацию цеха по переработке этих данных :) Представленная ниже схема – архитектура ЭВМ, она очень упрощена для удобства понимания в рамках данной статьи:
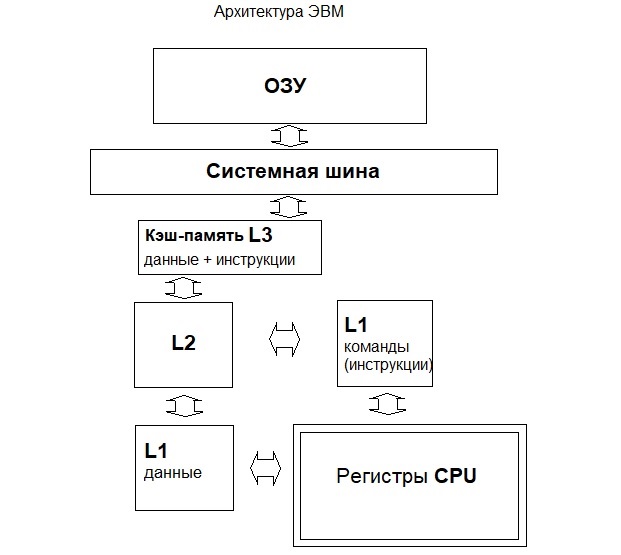
Итак, наша программа записывается в ОЗУ, далее она частями считывается и значения, которые требуют обработки (каких либо вычислений), посредством системной шины, поступают в кэш-память процессора (CPU). Да, помимо ОЗУ, у процессора есть своя память, которая намного меньше по объему, но гораздо (во много раз) быстрее ОЗУ. Так сказать, процессор имеет свой собственный сверхбыстрый буфер, имеющий разные уровни (L1, L2, L3). Дальнейшие операции производятся при помощи регистров процессора. Дело в том, что процессор работает только с собственными регистрами. Напрямую с ОЗУ он не взаимодействует. Сегмент кода (инструкций) из нашей программы, говорит процессору какую операцию необходимо применить над значениями, которые были записаны в соответствующие регистры. Все идущее ниже по тексту, будет рассмотрено на примере архитектуры процессоров семейства x86.
Регистры процессора – специальное место (ячейки памяти внутри процессора), где хранятся значения, записанные из программы (ОЗУ), при помощи системной шины, для которых необходимо сделать какие-либо вычисления.
После включения, процессор находится в режиме реальной адресации. Это режим, при котором любому процессу доступна вся память компьютера. При загрузке операционной системы, ОС переводит процессор в защищенный режим, при котором доступ к ресурсам для различных процессов разграничиваются и контролируются самой ОС.
Бит – минимальная единица информации, которой оперирует процессор. 1 байт = 8 бит и это составляет 1 “слово”. Итак, 1 слово = 8 бит = 1 байт или 2^8 = 256 значений. Существуют также двойные слова и т.д.
2 слова = 2^16 = 65 535
3 слова = 2^32 = 4 294 967 295
Байт, слово, двойное слово – это основные типы данных процессора. Для представления знака (отрицательное или положительное число) используется инверсия всех бит, а затем ко всем полученным битам прибавляется 1.
Для операций с плавающей точкой используется специальное устройство (FPU) внутри основного процессора с собственными регистрами и набором команд.
По назначению регистры процессора различаются на:
- аккумулятор — используется для хранения промежуточных результатов арифметических и логических операций и инструкций ввода-вывода;
- флаговые — хранят признаки результатов арифметических и логических операций;
- общего назначения — хранят операнды арифметических и логических выражений, индексы и адреса;
- индексные — хранят индексы исходных и целевых элементов массива;
- указательные — хранят указатели на специальные области памяти (указатель текущей операции, указатель базы, указатель стека);
- сегментные — хранят адреса и селекторы сегментов памяти;
- управляющие — хранят информацию, управляющую состоянием процессора, а также адреса системных таблиц.
Кроме того, процессор содержит наборы команд и инструкций. Например, расширения MMX - это встроенный набор дополнительных инструкций для более эффективной работы с большим потоком данных (изображения, видео, звук). По сути, это несколько новых типов данных, регистров и команд для повышения производительности.
Таким образом, данные, требующие обработки, поступают в регистры процессора. Процессор производит над ними, в виде машинных слов, необходимые операции и возвращает полученные значения обратно программе, которая, в свою очередь, взаимодействует с пользователем.
Итак, если очень упрощенно и простыми словами описать, что происходит с программой после ее запуска, то, пожалуй, на этом можно остановиться. Также хочу отметить, что в данной статье я рассмотрел пример программы написанной на компилируемом языке программирования (например, C, C++). То есть сформированный после компиляции машинный код, будет зависим от процессора (платформы), для которого он, собственно, и подготовлен (скомпилирован). Для итерпретируемого языка программирования (например Python) все будет выглядеть несколько иначе. Сам шаг компиляции там отсутствует, как таковой. Инструкции не исполняются целевым процессором, а считываются и исполняются другой программой (которая обычно написана на языке целевого процессора). Но, об этом я, возможно, напишу в следующих статьях.